
Ye’canny change the laws of physics, cap’n
ORIGINALLY POSTED 22nd May 2008
7,259 views on developerworks
So I haven’t forgotten I promised a part work on “Why Virtualise?”
Last week I was in Phoenix for the IBM CTRE. Each year IBM gathers 500+ of its technical achievers over the last 12 months and honors them with a few days of R&R, meeting with colleagues and of course some good food and wine. I was lucky enough to receive an award for my part in the performance enhancements we achieved last year with the 4.2.0 8G4 hardware release, and its record beating performance. At this point I have to commend JohnF for his sterling work on the code side and without whom we would not have made such a splash. Of course while in Phoenix I had to make a trip down to Tucson to catch up with a few folks and meet a few faces to match the names and voices I knew all too well!
My return to work on Monday resulted in some Business Partner education sessions and Tuesday was spent in a very interesting and worthwhile customer engagement. Today was spent with some visiting colleagues planning and discussing some new an interesting ideas. Tomorrow I hope to do some real work – hehe! Anyway, here is what started off as Part2, and merged into 3, and and bit of 4.
Why Virtualize – Parts 2,3 and a bit of 4
The Problem, The Solution and some of the Benefits
So why would you want to virtualize your storage. Almost every SVC customer presentation starts with just this, an answer to the all too common set of problems facing todays storage administrators. Management complexity, capacity under-utilisation, disparate systems, needing more capacity here and now, not enough staff, skills shortages within those staff… just to name a few, and thats just the half of it.
Today we live in a culture where take-overs (sorry acquisitions) – you never do hear about those hostile takeovers anymore…… Anyway its not just in the IT industry that acquiring a competitor to become the stronger player is common-place. Many of our customers are doing the same, and here is where a new problem arises. You acquire a business that has its own IT infrastructure, in particular the storage infrastructure. Today you may have a nice inter-operable SAN, but tomorrow can you accommodate the new assets. Servers and applications will be morphed to the common platform, but how do you make best use of a different vendors storage. You may have a skill shortage when working with new to you products, your hosts aren’t compatible with this now storage controller, box A needs firmware Y and box B needs firmware Z etc etc.
It would be nice if your infrastructure could just suck in the extra capacity provided, and nothing else needed to change. A ‘Holy Grail’ maybe, or maybe its a reality… yup, you guessed it – SVC. So as long as its on the SVC support matrix, and there is not much that isn’t these days, and of course if its not on there you can request an RPQ… stick the controllers behind the SVC, create a new storage pool and instant new capacity, available to all the hosts already using the SVC cluster and no change is needed on any of the hosts, same firmware, device driver, multipathing as they were using yesterday.
(I’ve noticed I start too many paragraphs with ‘anyway’)
Anyway 😉 , lets go back a few years to when the SVC project was just beginning – or even just before it was chartered. Infact, lets go back almost half a century before that and start from the beginning.
In 1956 IBM released the RAMAC-350 – the first hard disk drive, as part of the IBM 305 Random Access Method for Accounting and Control. The disk storage unit itself was more than a tonne in weight, had tracks that you could actually see with the naked eye and stored a whopping 4.4 MB of data. This was however a revolution (excuse the pun 1.2K RPM infact), a random access device, when compared with tapes and punch-cards for sure.
Over the next few years, aerial density increases were pretty easy to come by, you could shrink the distance between tracks, and hugely increase the tracks per inch, thus increasing the capacity. Meanwhile the techniques got better and better and the demand increased, so cost was reducing. Basically next year you could pretty much have another one for half the price. So for a while, addictions were met, and storage capacity was tracking close to 100% CAGR.
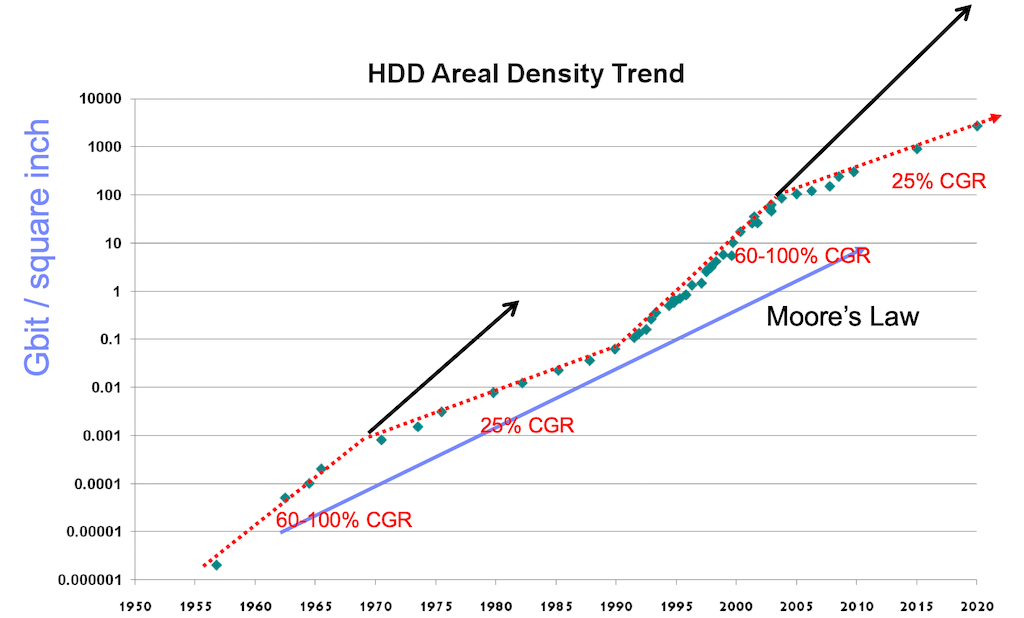
However, (thats another common word I seem to use to start a paragraph) – around about 1970 things started getting a bit more difficult, the low hanging fruit had gone and now some real innovation was needed. Things progressed but there was a definite slow down in density growth. By now we are in the first heay-day of the IBM Mainframe. Since we’d now hooked you on this substance [storage] that was getting cheaper and you needed more and more of to survive we came up with various techniques that made what you had last longer. To this day most Mainframe systems run at a processor and storage utilisation of about 90% (Yes, may seem unfeasible to open systems folks, but we are getting there – VMware allows Windows boxes to go from an average of 15% utilisation to closer to 75% and storage virtualization from 30% to around 85%)
So during the next 19 years the Mainframe ruled, then another group of smart IBM people (Stuart Parkin et al) came up with a practical GMR head that could be manufactured, [The Nobel committee some 25 years after the original GMR head design (Gruenberg, Fert) was conceived decide this was quite a revolutionary event.] For the last 10 years we’ve been happily selling the storage drug and our addicts have been consuming at a rate greater than ever expected.
In 1965 Intel co-founder Gordon Moore published, what is know as Moore’s law relating to silicon based growth rates, and on average storage had been, during its peak growth periods, tracking pretty nicely to this law. Moore’s Law – still holds, certainly for silicon today.
Because R&D runs about 5-7 years ahead of ‘products’ we saw the down-turn coming, after a year of so of thinking something would turn up it was clear that nothing was going to and we had pretty much hit the ‘laws of physics’ when it came to bits per inch. So we looked back to the past, and how we’d solved the problems back in the ’70s when we last hit this slowdown and the idea behind SVC as we know it today was born.
The idea is simple, how can we get the best utilisation out of the stuff we have today. Meanwhile the Almaden Research Labs were working on a clustered storage architecture, something that would scale linearly as you added more compute nodes. The prototype cluster management, cluster communication and state engines were developed and the concept proved. At the time, the folks were looking at using common parts to build the compute engines, and the name COMPASS was used for the project – COMmon PArts Storage Subsystem. There used to be a major no-no on IBM publishing internal project names (not exactly sure why) but I know its known out there in the public domain that SVC was originally called Lodestone during the first few years of development. If you follow the link, you will work out the link between Lodestone and Compass.
If you track the last few years of drive developement, it turns out we were right, things really have slowed down. (Of course it could be related to the fact that IBM realised HDD had become a commodity and off-loaded the drive business to HDS, who are now looking to do the same – or maybe its because IBM is investing less money in R&D for HDD enhancements – you decide… Ye’canny change the laws of physics…
It was around about this time that I joined the SVC development team, having been writing device drivers and configuration interfaces/host software for previous storage products I helped architect the configuration the interfaces for SVC, taking the input from the CIM and CLI interfaces (working on the SMI-S standard too) and turning them into our cluster state transitions that would create, modify and manipulate the various objects internal to the cluster.
Its funny looking back now, but we were so deep into the idea of making better utilisation of what you had, providing a single management interface to the cluster (and hence all of what you have now with SVC) and the support of as many storage controllers out of the box that for a few months we had missed the killer app. Online data-migration.
It could be said the same is true for pretty much all of the people that are initially interested in SVC. I love the reaction, that moment of realisation it produces. It makes it all worthwhile.
Almost every customer engagement I’ve been involved with has the same turning point during the day. You start talking about the ‘virtues of virtualization’, discussing the various pain points they have today, the vendor-lockin they may be experiencing with certain closed proprietary vendors and we can offer a way out – a new way to look at things – and a new way to think of storage, nice but how do I get there…
This can be summed up when you come to online storage data-migration. In a traditional environment it goes something like this :
- Stop the application(s)
- Copy the data – using some means – LAN, SAN etc
- Re-map the new LUNs – zoning, remapping in new storage, reconfigure hosts
- Re-start application(s)
The elapsed time here can vary from days to months – a real pain, especially when things go off-lease or are swapped out every 2-3 years. If you spend 3 months during this migration (at each end of the cycle) you are only really getting 2 to 2.5 years of useful life out your storage, and a lot of overtime and weekend/evening work for your storage admins.
In an SVC environment it is :
- Move the data
Thats it. Nothing more, no down time, no weekend/evening working, no grief. We even pace the migrations so you can kick off the whole lot in a single go and leave it to progress. Average elapsed time, several days maximum. This can all be done during the working day, or scheduled to run less aggressively during the day and more aggressively at night.
There is obviously extra workload going on during this time, but here it is, tried and trusted, 3,500+ instances running in everyday production and reaping not only the consolidation, utilisation, power and cooling benefits of using more of what you have, but also eliminating the majority of those serious pain points other vendors create and your IT staff complain about on a day to day basis.
The future is now, the future is; maybe a colour between yellow and red; but really its all virtual to me.
Source:
Disk drive evolution – “Technological impact of magnetic hard disk
drives on storage systems”, Grochowski & Halem, IBM Systems Journal
Vol 42, number 2, 2003
Moore’s ‘law’ – “Cramming more components onto
integrated circuits”, Gordon Moore, Electronics, Vol 38, Number 8,
April 19th 1965 [et seq.]
Credit also to S.P.Legg, IBM 2008 for correlation, reference and metaphors.
All images attached here are (c) Copyright IBM 2007





Leave a comment