
BW: Its been a while since I had a guest post and who better to complete the series of articles discussing the latest Policy Based Replication functionality the replication development lead himself, Chris Bulmer.
[BW: Where I have added some commentary it is in this blue italic text.]
Policy-based replication
IBM SAN Volume Controller, and later IBM Storwize and IBM FlashSystem products, have had replication capabilities since the first release, way back in the early 2000s and many of the concepts (and code) haven’t changed dramatically since then. With a shift in the industry to highly scalable, automation-friendly and self-managing storage the existing Remote Copy concepts were proving to be an inhibitor to our goals for replication. So, several years ago (pre COVID-19!) we began working on a plan for a ground-up re-design and re-implementation of our entire replication codebase, which led to what is now known as policy-based replication. This feature is available in Spectrum Virtualize version 8.5.2 on all the products in the portfolio except the FlashSystem 50xx models. The existing Remote Copy features are still available on all products, and it won’t automatically switch to using policy-based replication when you upgrade.
What is policy-based replication?
The idea, if you couldn’t guess from the name, is that replication is managed using policies (imaginatively named replication policies) and by applying a replication policy to a volume group the system automatically configures and manages the replication for all volumes in the volume group. The system automatically creates and configures the volumes on the DR system and there’s no relationships or consistency groups to manage – all the configuration is managed on the volume group.
The replication policy has several attributes, including a topology that defines how replication will behave; in the first release there’s a single topology option: 2-site-async-dr. This is asynchronous replication between two systems. The policy also must specify the recovery point objective (RPO) for and the two locations. A location consists of the system name plus which I/O group within that system should be used.
A system supports up to 32 replication policies and we believe that’s enough for replicating between multiple different locations with different RPOs, but it’s easy for us to increase this number in the future if we find we need to allow more.
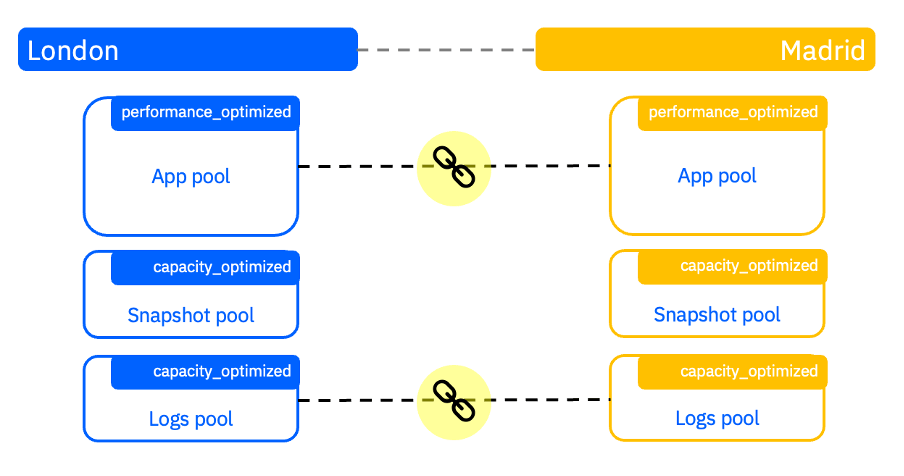
Say I have two IBM FlashSystem 5200 systems, one in London (named London) and the other in Madrid (named Madrid), I can create a replication policy that defines how replication should be configured between these systems.

Pool Linkage
As part of the setup of replication using the GUI, you’ll be guided through creating a replication policy as well as linking pools between systems. This new linking step instructs the system which pool(s) to use to create volumes in the recovery system and encourages the use of provisioning policies (although it’s not required!) to define the additional capacity savings to use when creating volumes.
By following the replication policy, pool links and provisioning policies the system has all the information it needs to provision volumes in the remote system automatically while allowing for much of the flexibility you’d have if you configured it manually.
Production and Recovery
With that configured, I can create a volume group (or use an existing volume group) and specify a replication policy to use. The system will then create a copy of the volume group on the remote system with the same name.
The system where the volume group was created will be automatically defined as the production copy and the remote volume group will be the recovery copy.
Creating, modifying and deleting volumes is performed from the production copy and the system will make the appropriate changes to the recovery copy.
[BW: Note While the replication policy is in place you cannot directly make any changes to the recovery copy, volumes, or volume group – they are essentially like read only objects – to make changes you must change the production copy and the recovery copy will synchronoize]
The volume group acts as the unit of consistency and every volume in the volume group will be mutually consistent – this means the volume group effectively replaces the need for a consistency group. The volume group provides a common definition of volumes for snapshots and SafeGuarded Copy too, so you don’t have to manage these features separately – just add the policies to the volume group and you’re done!

If I create, or add an existing volume, to a volume group with a replication policy then a recovery copy of the volume will be created in the remote system and the change volumes will be created automatically. Unlike with Remote Copy, the change volumes are created and managed by the system and by default they are hidden as there’s nothing useful you can do with them, but it’s important to remember that they exist when planning for capacity and volume counts. I can even make configuration changes when the systems are disconnected, and it will automatically catch up the configuration changes when they reconnect without any intervention, making it very easy for automation (and humans).
Monitoring & Managing
Configuring and setup of replication is only one of the major improvements that the feature brings. It overhauled the monitoring of replication to include native monitoring of the recovery point and alerting if the recovery point of the volume group exceeds the RPO defined in the replication policy.
Replication is now configured, managed and monitored using the volume group panels in the GUI, rather than the copy services panels (although the partnership is still configured from the copy services section).

Independence
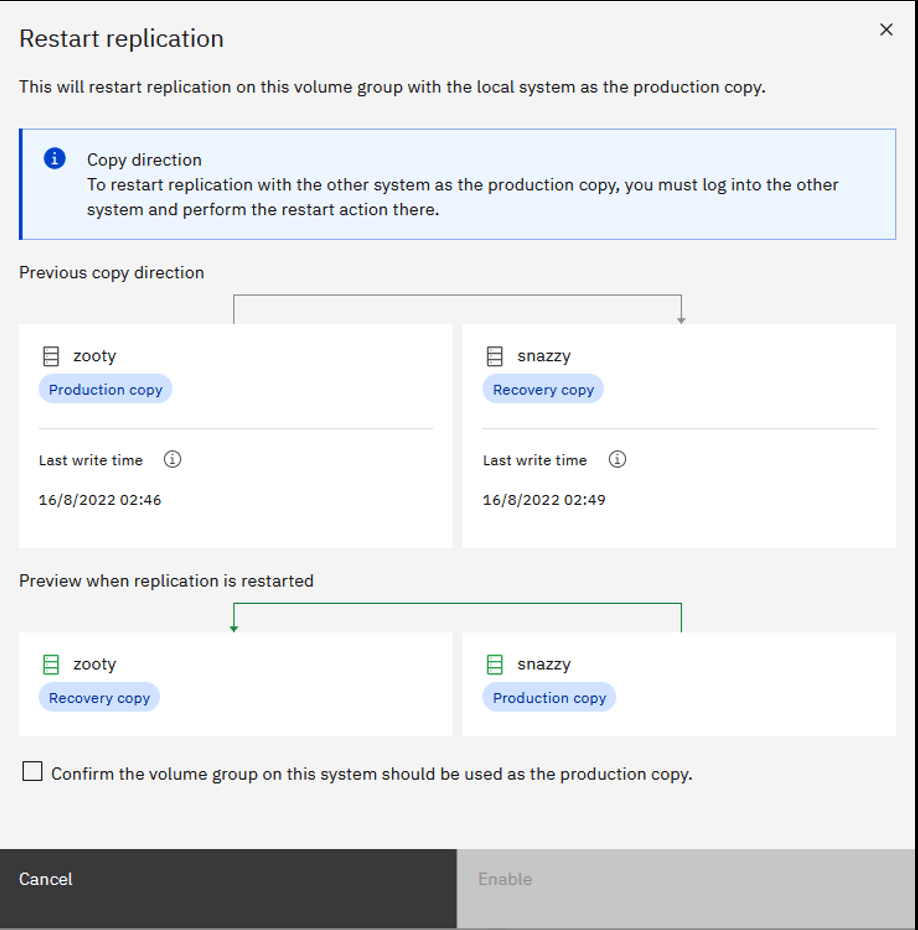
If you need to failover or gain access to the recovery copy of the volume group, then the volume group can be made independent. This is an action that can only be performed when logged into the recovery system for the volume group. It will make the current recovery point accessible to applications and make the configuration match the recovery point – this means it will delete any volumes that are not part of the recovery point, such as if I’d added an existing volume to the volume group and it hasn’t yet synchronised.
An independent volume group is accessible from both systems and permits configuration actions at both systems. When you’re ready, you can restart replication by specifying which system you want to be the production system. If you use the GUI, it’ll illustrate what’s about to happen at every phase.
[BW to avoid human error when restarting!]
Adaptive Replication
I said at the beginning of this post that it’s a complete re-design and re-implementation and that extends to more than just the configuration side.
There are two modes of replication, and it will automatically switch volume groups between snapshot-based replication (like Global Mirror with Change Volumes) and journal-based replication (like regular Global Mirror) depending on the throughput of the link and the host write rate to avoid causing application performance problems. What this means in practice is no more 1920 events. Perhaps I should emphasize that further…
NO MORE 1920 EVENTS!
Instead, the recovery point will increase if replication cannot keep up and it may switch to the more bandwidth-efficient cycling mode (snapshot-based replication) to remain within RPO. This is all managed by the system with the objective of ensuring that every volume group remains within the RPO defined by the replication policy. If you have multiple volume groups using replication policies with different RPOs then it will consider that as part of decision making when deciding which mode volume groups should use. The idea is that you should never need to worry about how it’s replicating, only that it’s achieving the recovery point objective.
[BW: It should be noted that if you only have one Volume Group we can’t make a priority call, but even if you use just one RPO setting in your policy then we check which Volume Groups are using the most bandwidth – but it is worth considering what are your most important systems / and using Volume Groups / RPO settings accordingly]
Performance ++
The I/O processing has been completely redesigned too and the improvements are significant…
A single I/O group FlashSystem 9500 using PBR can outperform four I/O groups using Global Mirror in perfect lab conditions. I’ll save the details of how it achieves this for another time given this post is already getting a little long.
So all-in-all, we strongly believe that this is a great improvement both in terms of usability and performance versus Global Mirror or Global Mirror with Change Volumes and we hope that you agree. We have plenty of enhancements planned too so watch this space!
[BW: Many thanks again to Chris for taking the time to write this article, we look forward to your next installment!]





Leave a comment