
When I introduced the updates in Spectrum Virtualize 8.3.1 I promised a dedicated post discussing the details around the new DRAID dynamic expansion feature. Before we dive in, there are some DRAID basic terms that you need to understand.
DRAID Basics
Check out the DRAID – How it Works post for more details but in summary a DRAID array is made up of a given number of component drives (often called a pack or row) which is usually larger than the RAID geometry. The geometry being the normal n+P+Q layout. Each drive provides a strip that makes up a stripe. The stripe width being the n+P+Q, which will always be lower than the component count. Additionally, between 1 and 4 spare areas can be configured per DRAID array.
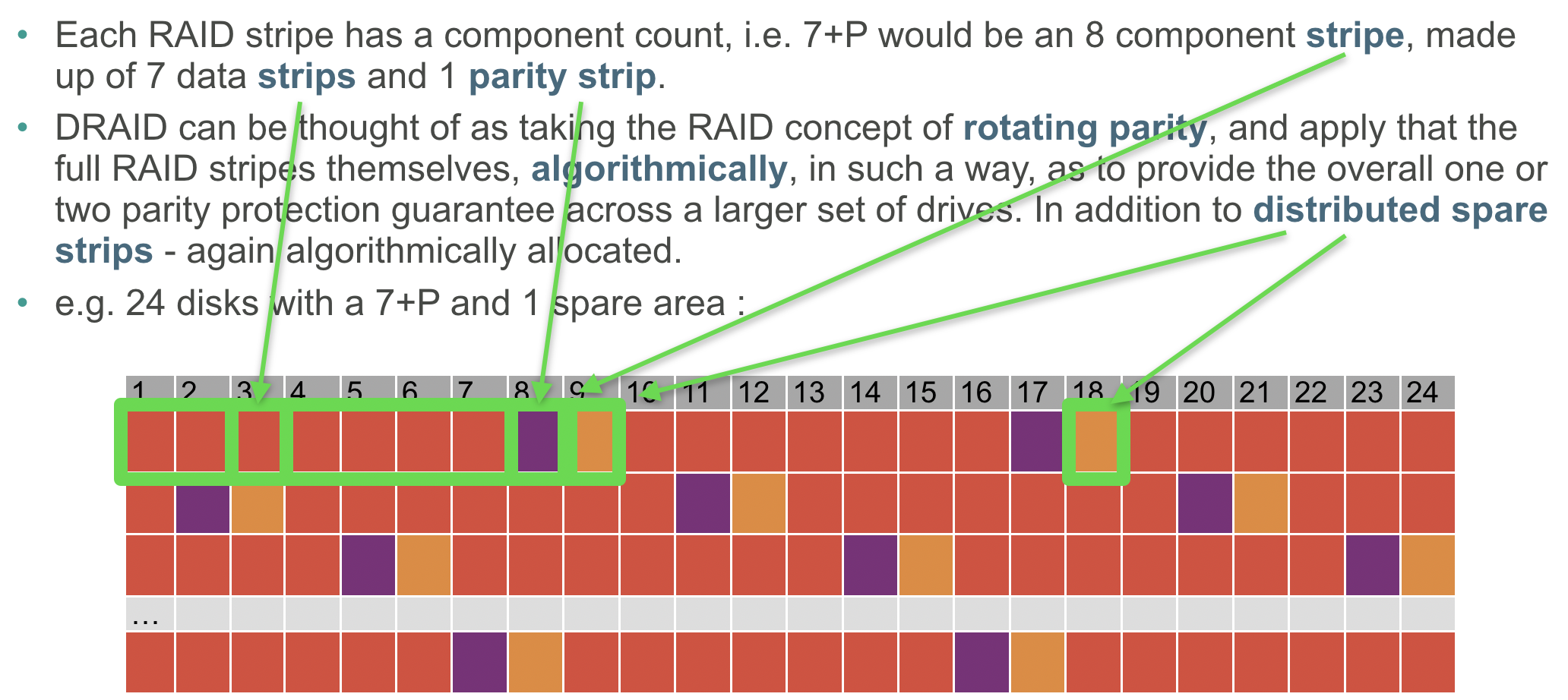
In this example slide the component count is 24, the geometry is 7+P and there is 1 spare area. Please note that the actual algorithmic layout is not represented, this is just for simple illustration of the terms used. In reality the 7+P stripe would appear to be dispersed randomly across 8 of the 24 drives for each stripe!
So in summary the terms we will use are :
| component count | the number of drives in the DRAID array |
| strip | a chunk (256KB) of capacity on a single drive |
| stripe | a set of strips that make up a single instance of the chosen geometry |
| stripe width | the count of strips that make up a stripe |
| geometry | the chosen protection and stripe width, i.e. 8+P+Q |
| spare areas | the number of distributed spare strips that are available for each stripe |
What is DRAID Expansion?
DRAID Expansion provides the ability for you to dynamically add one or more drives and increase the component count of an existing in use DRAID array. The expansion process is dynamic, and non-distruptive, i.e. you can do this and continue to access the data on the DRAID array.
New drives are integrated and data is re-striped to maintain the algorithm placement of strips across the existing and new components.
Each stripe is handled in turn, that is, the data in the existing stripe is re-distributed to ensure the DRAID protection across the new larger set of component drives.
All pools and volumes remain online and available during the expansion.
What can be added?
Between 1 and 12 drives can be added in a single operation or task. That is, you can decide to expand in multiples of up to 12 drives. If you need to add more than 12 drives to a DRAID array, this would involve multiple serialised tasks.
Only one expansion task can be in progress on a given DRAID array at any point in time. In addition, only one expansion is permitted per storage pool at any point in time. Up to four expansions can run in parallel on a single system, assuming you have four or more pools., i.e. one per pool.
New drives can be used to increase the number of spare areas. Stick to a rough rule of 1 spare per 24 drives.

What should I know?
It kind of goes without saying, but I will say it anyway – only add drives that match the same capability as those already in the DRAID array. Both in terms of performance and capacity.
Provision has been made to override this in extreme exception cases, always try to add the same class or tier of drive. You can override and add a superior drive class, but you won’t see the benefit and are wasting performance. Same goes for capacity, larger capacity drives can be added, but the usable capacity will match the smaller existing drives and the additional capacity will be unusable.
Only the component count, or number of spare areas can be increased. You cannot change the geometry, a 10+P+Q will remain a 10+P+Q. (I recommend going for the largest stripe width you can – so 14+P+Q ideally on day 1)
What is the impact during the expansion? And how long will it take?
The idea is to minimise the impact to the end user application. The expansion is therefore a background task that will take many hours, days, or even weeks to complete. The exact time will be dictated by how busy the DRAID array is during the expansion, the performance and capacity of the component drives. Think days… the GUI and CLI will show an ‘estimated completion date/time’
As the expansion will take some time to complete, the new free space is drip fed into the mdisk/pool. So when a complete row has been expanded to make use of the new component count, so some more capacity will be available to be used. Therefore during the expansion you will see the pool capacity gradually increase until the expansion is completed. i.e. you don’t have to wait until the entire expansion completes before using some of the new free space.
What happens if a drive fails during expansion?
The rebuild takes priority. Wherever the expansion has got to, it pauses, begins the distributed rebuild of the missing strips onto one of the spare areas and continues until the rebuild completes.
Only when the rebuild is finished, the DRAID array is online (not degraded) will the expansion process resume.
Note that the expansion does take priority over the build-back. Build-back is the final stage that a DRAID array requires when you replace the failed drive, where is copies the data back from the distributed spare areas onto the replacement drive to re-establish the original algorithmic layout.
What cannot be done?
As mentioned before, expansion does not allow you to change the stripe width or geometry. If you want to migrate from one geometry to another you would need to use migration functions to vacate the existing DRAID array of volume data, destroy and rebuild it. Its worth noting that if you have spare capacity to do this, and you are expanding a DRAID array with large numbers of drives, this may actually still be quicker.
Finally, no, you cannot shrink the component count, the function is called expansion afterall 😉
One at a time, or all at once? (Added 28/5/2021)
The process of expanding the RAID array requires all existing data in the array to be moved around so that it is striped across the new set of drives. Therefore the amount of work required to complete the expansion is the basically the same whether you add one drive or 12 drives.
So if you have multiple drives to add to an array – add them in one CLI command (or in batches of 12). It will take much less time to do it this way than to do it one at a time.
What else?
I think I’ve answered most of the frequently asked questions I’ve had so far about DRAID expansion, but if I’ve missed something, or you have a question that I didn’t answer here – ask in the comments and I will answer there and update the post.





Leave a comment