
ORIGINALLY POSTED 10th May 2018
9,873 views on developerworks
Hopefully you manage(d) to join the Reducing Storage Costs webinar, but if not, here is a brief look at what we announced today – May 10th.
Spectrum Virtualize v8.1.3
Data Reduction Pools – Deduplication
I spent some time in my v8.1.2 post discussing how Data Reduction Pools were a re-imagining of the storage pool concept. Mainly because we went back to the drawing board and asked ourselves what is it that a storage pool needs to provide in today’s all flash, and future storage class memory world. Not only from a data effficiency point of view, in terms of Compression and De-duplication, but what micro services do we need to provide to the storage pool, and to the other components that make up a modern storage system – DRAID, Caching, Thin Provisioning etc etc
Today we have announced that with v8.1.3 of Spectrum Virtualize you can now add de-duplicated volumes to your Data Reduction Pools. Just like compression, thin provisioning and unmap features, de-duplication makes use of the micro-services we have provided to DRP’s – garbage collection, easy tier ‘binning’, log structured array allocation, and fine 8KB grain sizes.
I plan to create a series of posts over the next few weeks/months delving deeper into data reduction pools, how they work, what it means to you, so that by the time you are looking to deploy them you have all the technical details you need – anyone who attended my sessions last week in Orlando will have had a basic introduction to the topics I will cover.
Needless to say a Data Reduction Pool is designed for flash and solid state. What do we really mean by this?
HDD vs SSD / Flash / PCM
When designing advanced functions, like compression, to work well in an HDD environment you are mainly concerned about IOPs. Each HDD had a limited number of IOPs and as such that limit dictated the overall performance. With an HDD the overall latency was dominated by the rotational and seek latency portion. The actual data transfer, read or write, was a tiny part of the latency, since the head was now in the right place, it took not much longer to continue reading or writing the same track. Therefore, a 32KB I/O didn’t take much longer, in terms of data transfer than a 16KB I/O.
SSD, Flash or any of the new (as yet unavailable) Solid State storage classes are very different. IOPs are almost free, i.e. lots of them available, but here, because there is no seek or rotation, the accessing of the correct location is pretty much instant, and the actual I/O latency is now dictated by the size of the data transfer. So with thee technologies, a 32KB I/O takes almost twice as long as a 16KB I/O
Its for this reason, and a few others I will cover in due time, that using more IOPs, but reducing block sizes can give a much lower, but more importantly predictable and consistent latency overall. Its that consistency and predictability that we all strive for. Reducing the chunk or grain size to an 8KB boundary means we can complete a 32KB I/O, in theory in 1/4 of the time normally needed, but issuing 4x 8KB in parallel, yes using up some of the IOPs, but ensuring low latency.
De-duplication
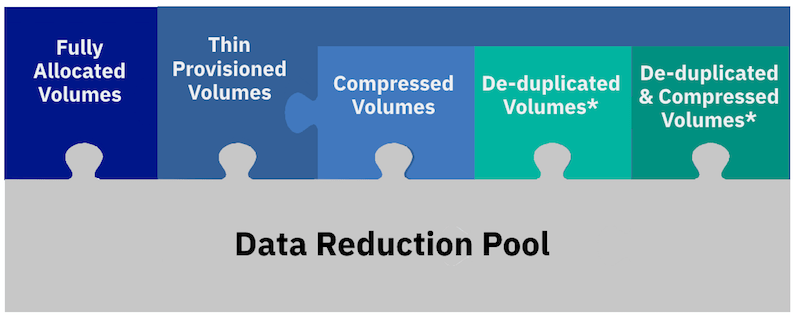
With v8.1.3 you can now have Fully Allocated, Thin Provisioned, Compressed, De-duplicated and De-duplicated then Compressed volumes inside a single Data Reduction Pool. Allowing you to mix and match, and not forcing the meta-data I/O amplification on every volume on the system. This is also inline, so data is de-duplicated before it reaches lower cache.
The scope of de-duplication is within a single Data Reduction Pool. Important therefore not to store your backup’s in the same pool…
v8.1.3 also lifts some of the restrictions previously see on v8.1.2 and Data Reduction Pools.
So here it is, finally – can I say that – I guess I did – the function that has been much talked about.
The * in the image means, with v8.1.3 code.
What savings can I expect?
Now I’m a realist when it comes to this. The reality is that de-duplication is not compression. With compression on day1 you get 2:1 – if your application doesn’t change, and the data type is the same, on day365 you will still get 2:1 – De-duplication varies over time… on day 1 you may get 3:1 but over time this will reduce – as more data gets changed, so it -un-de-dupes to others… you delete a volume, and suddenly you need to copy a load of data into another volume that was de-duped etc etc
Any vendor who sells you on 5:1 or more…. laugh at them… ask them for the real number… what do they actually see in real life, excluding Thin Provisioning, and at their average customer… I know for a fact it will be more like 3:1 – and to be conservative 2.5:1 (from real life experience of said vendors in real life large scale production environments)
So I’d say that was a reasonable place to be, with de-duplication and then compression, assume something like 2.5:1 – hey you get more after time – great – you can provision some more capacity – but don’t go all out on day 1 – maybe start conservative at 2:1 – particularly important when provisioning over-provisioned capacity to SVC. You can always create more mdisk space in the future. You maybe one of the lukcy ones and really get 4:1 or more, but you will be in the minority -and remember for an average of 3:1 – someone will get 5:1 but someone else will get 1:1 …
We do have the de-duplimator tool, the same one that is available for A9000, but in reality, having to scan the entire data set to get a valid number in impractical for most people, so assume low, and be suprised if you get high!
The launch overview blogs that talk more about the benefits and Spectrum Storage journey to multi cloud providers, as well as the launch blog discussing Data Reduction.
RestAPI Support
v8.1.3 also bring a Rest API to map https JSON/URI encoded requests over to CLI commands. There is as direct as possible translation between the CLI options and the JSON encoding. For example:
| POST HTTP/1.1 <api_ip>/rest/chvdisk/0 {“name”: “new_vdisk_name”} |
Results in the command :
| chvdisk -name “new_vdisk_name” 0 |
Initial handshake is via userid/password challenge which establishes the SSL connection. More details can be found in the knowledge center for v8.1.3
Spectrum Virtualize for Public Cloud Enhancements
Today we also announced the next round of enhancements to our IBM Cloud offering of Spectrum Virtualize. These enhancements include :
- 8 Node Cluster support
- Enhancements to the available performance
- Simplified install procedures
For more details see the launch blog.
IBM Storage Insights
The world wide GA of our class leading cognitive support and analytics software. Re-branded from Spectrum Control Insights Foundations, IBM Storage Insights is available to all IBM customers as a cloud portal to view your IBM Storage estate, file problem reports, upload support details and provide you with AI ‘insights’ into your infrastructure. Upgrading to Insights Pro allows you to get the full performance and provisioning support available from on-prem Spectrum Control but with the ease of a cloud portal.
Everyone I’ve discussed this with is very exited about this next gen support and management offering, and to learn more see the launch blog.





Leave a comment