
ORIGINALLY POSTED 9th March 2017
14,783 views on developerworks
I completely missed the announcement a couple of weeks ago for version 7.8.1 of the Spectrum Virtualize software. Traveling too much at the end of last month and forgot to post an update on whats new.
This release I am dubbing the ‘customer council’ release. Last year we started a customer council, a by invitation, group of key customers using Spectrum Virtualize in one form or another, and have been for some time. The idea being to get a good insight into how they are using it, what pain points they have, and how we could improve things to make the products even better.
So here is 7.8.1 which includes a large number of features that came directly out of that, as well as picking off a few of our top requests for enhancement from the RFE pages.
Platforms
Since we refreshed the entire product line last year, from V5000 in Q2, through V7000, SVC and V9000 in Q3 and the new High Density expansion in Q4, there isn’t any hardware updates this time round. Well apart from the Software only version… Last year we also introduced the Software only version of Spectrum Virtualize, or SVC as Software as its often called. SVCaS initially supports bare metal for Lenovo M5 servers, but we are now adding Supermicro servers to the list.
Performance
Last year we also added a new ‘Host Cluster’ object to the management model. Host Clusters allow you to group host objects into a single cluster and map volumes directly to the cluster object. All hosts, and hence WWPN that are within the cluster will get the same volume mapping, critically with the same SCSI IDs etc. This should simplify management of clustered host systems, VMware in particular where today people worked around via very large host objects, or manual mapping planning. Host Clusters were added to the CLI in 4Q last year, but they are now fully implemented in the GUI interface as of 7.8.1
In addition to the Host Cluster objects, 7.8.1 also add the ability to apply QoS to the Host Cluster in terms of IOPs and or MBs. Therefore building on the fine grained I/O throttling that was re-vamped in 2015. This means you can specify a cluster limit on performance, the system will take care of spreading evenly or not, the load within the hosts and volumes that make up that Host Cluster.
Protocols and Networks
We’ve always had really good SAN Congestion reporting, via buffer credit starvation reporting in Spectrum Control and via the XML statistics reporting, but the 16Gbit HBA didn’t include this measure. That has now been addressed and from 7.8.1. there are new reports in the XML that will be picked up by Spectrum Control in due course.
Copy Services
Here we get to address our #1 RFE request, and some pain points as raised by the customer council.

Yes, at long last you can now expand (or shrink?!) volumes that belong to an MM or GM relationship. As with all things there are some caveats. The volumes must be thin provisioned, or compressed, and the secondary can only ever exist in a state where it is ‘temporarily’ larger than the primary. Volumes can be VDM mirrored, but they must meet the requirements here for VDM expand – ie. the volume mirror is synchronised. Similarly the GM/MM relationship must be synchronised when the resize is issued.
Not supported are GMCV volumes – GlobalMirror with Change Volumes, HyperSwap volumes, Fully allocated volumes, and if the new Consistency Protection is enabled on GM.

Speaking of which, you can now create a FlashCopy of a target GM/MM volume which is consistent_stopped.
That is, imagine you have some kind of link issue that stops replication. The primary continues and we update the bitmap of which grains have been changed, so we can sync just the changes when the link is restored. Now if a disaster were to hit the primary at this time, at least we have a consistent copy at the secondary site, that while some time behind the primary is usable.
Assume the link gets restored and you now want to start the re-sync operation. If you start the FlashCopy mapping at the secondary, we maintain a consistent copy of the secondary volume during the re-sync operation – which by its very nature makes the secondary volume temporarily inconsistent while the bitmap if changes is used. i.e. the re-sync has no concept of what order the changes were applied, just that the changes have been applied. If you suffer a disaster at the primary during the re-sync, you can at least reverse the FlashCopy and regain a consistent secondary copy.
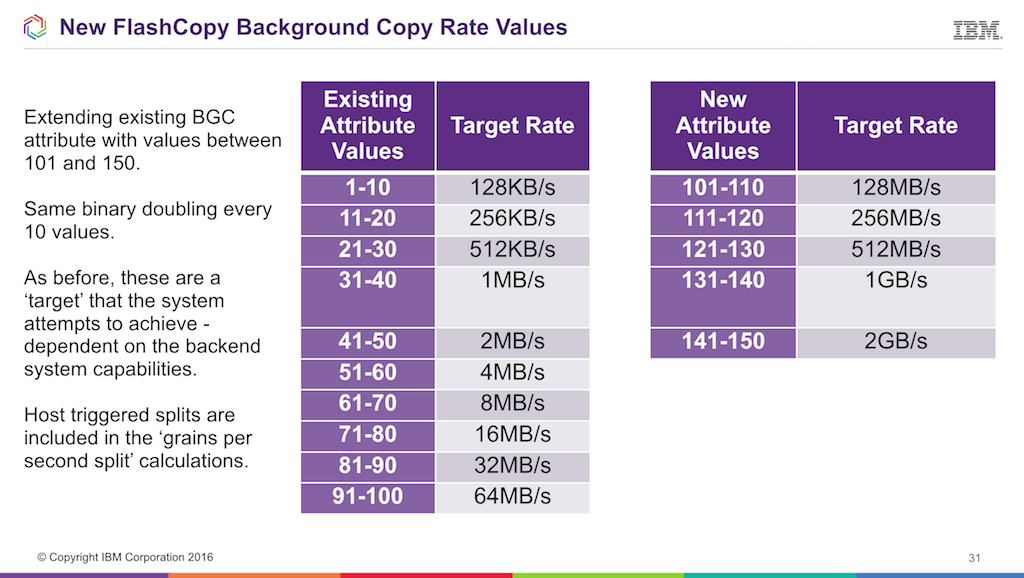
Way back in about 2001 when we (I) was designing the CLI interface, and so setting a lot of the performance based requirements on user tasks, we discussed what the background copy (BGC) rates should be. Given that even with RAID, when you read and write, you end up with the performance of a single HDD, which can do about 100MB/s (even today) we decided to go with a maximum of 64MB/s. Move on 16 years and now we have lots of flash storage that is capable of way more than that. Now, I can also be partly blamed for not catching that the developers had implemented a binary doubling scale for the ‘percentage’ where 100 is actually double 90. It was supposed to be an actual percentage, so 50 should have been 32MB/s etc – but we just dropped the percentage from the field 😉
Anyway, since we have this legacy the ‘percentage’ value can now be increased to 150… and follows the same binary doubling of throughput.
Proactive Host Failover
PS. One other thing that isn’t in the RFA is a new functionality making use of TPGS in SCSI that enables proactive host failiover as an alternative fast failover when NPIV isn’t being used. Basically as a node is gracefully leaving the cluster (temporarily for reset, failure etc or permanently for an rmnode) then we will notify the servers via their active paths that the paths are going away. Thus enabling fast failover without the need to wait for multi path timeouts. More on this soon.
For full press release, RFA information see here






Leave a comment