
In Part1 we saw how partitions form the basic building blocks of PBHA, how to create and manage partitions, some considerations for “getting it right” on day1 and how to make the partition and its objects into a Highly Available Partition.
In Part2 we looked at the different types of HA deployment that are possible, from full HA, to HA storage and to DR like HA – including different host access modes, such as uniform and non-uniform.
In these final part(s) we look at how each of the types defined in Part2 handle different failure scenarios.
- Part 3a discussed failure scenarios for fully Active/Active configurations
- Part 3b covers Active/Passive configurations, and is a long read I’m afraid!
- Part3c here, covers DR like configurations.
[I had originally planned to cover all deployment types here, but the post was too long, Part3 will be in itself 3a,b,c]
Legend :

Part3c – Comparing Availability – Active/Standby – DR Like
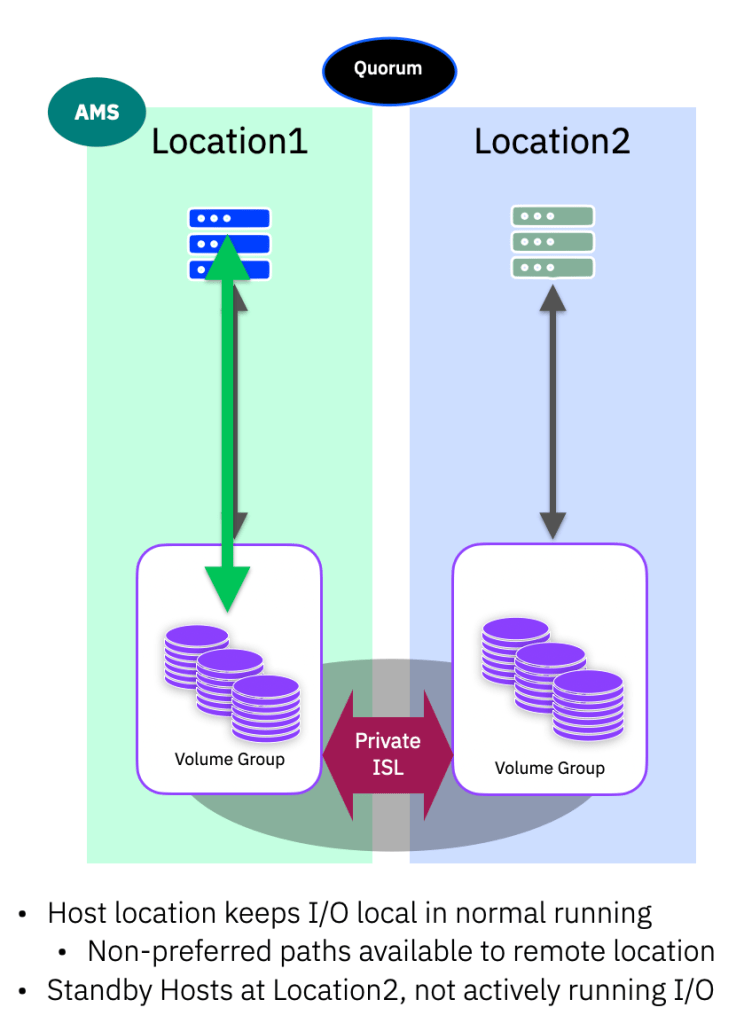
Normal Running
The main difference between Active/Passive and DR like configurations is that an application is generally only running at the AMS location. That is, the application only runs at one location and any access at the non-AMS location will require an application failover task – however the storage is generally always available at both locations. The active location should be aligned with the AMS and the cross-site public-ISL links are not configured in any form.
Note: The application itself is not expected to have any HA like access control mechanisms. It therefore is left to the user to ENSURE that no I/O is performed at the non-AMS location. Any such I/O could result in data corruption as the storage is always operating in an Active/Active manner and any changes made at the non-AMS will be mirrored to the AMS location, thus causing inconsistency in the data expected by the application running at the AMS.
Thus: It would be recommended that you either disable the host/storage zoneset at the non-AMS, or do not map the volumes at the non-AMS hosts during normal running. Part of the “application failover” tasks, in the event of a DR, must include the re-enabling of the required zoneset, or the mapping of the volumes to the hosts at the non-AMS location.
From a host/application perspective, this configuration looks more like a standard synchronous mirroring setup.
The hosts at location2 are in a pseudo-offline mode, i.e. they can, by default, see the storage at the non-AMS location, but no active workloads should be running on those hosts. (Unless measures have been taken as outlined in the notes above)
Pathing, in terms of optimised/non-optimised (preferred/non-preferred) follows the usual AMS preferred rules. So all paths to the storage at the AMS from hosts marked in the AMS location will be preferred and there will be no non-preferred paths visble, as there is no public-ISL cross site pathing.
The IP quorum device must still be deployed, and would keep the AMS active in the event of a link loss (split-brain) where both locations are still available.
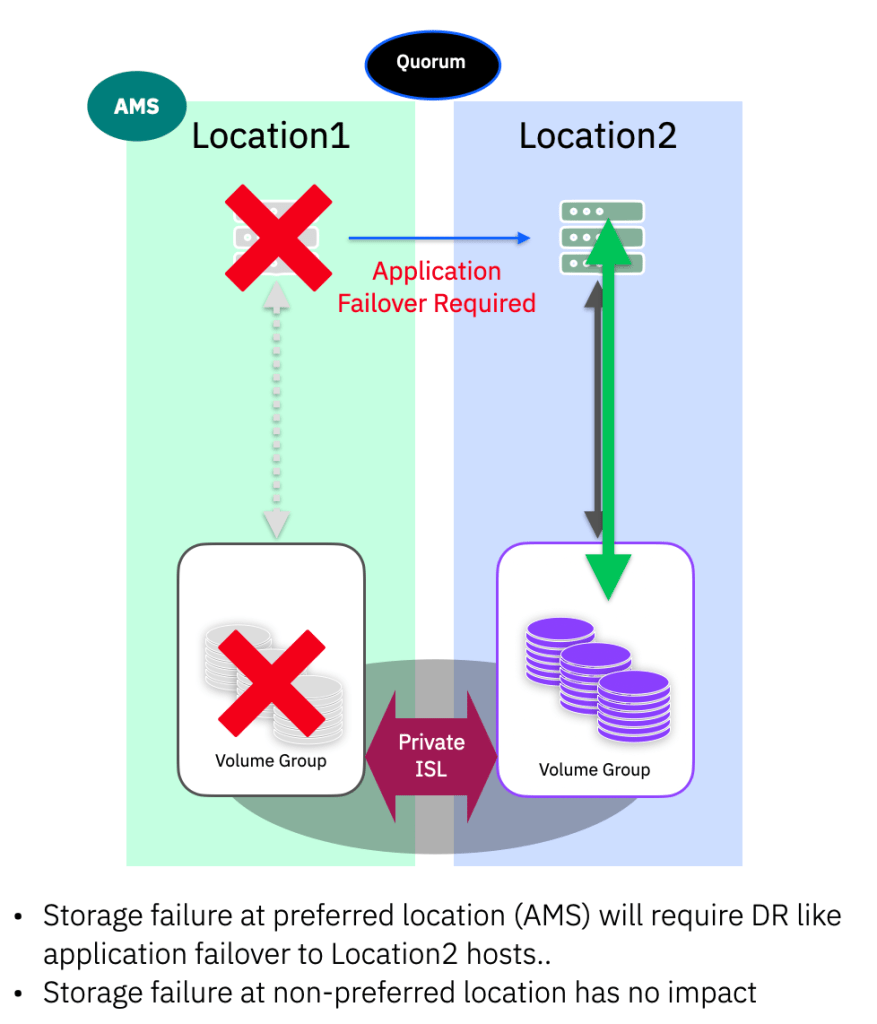
Storage Failure
In the case of a storage failure, this could be the system as a whole (power issue for example) or multiple-drive failures that cause a pool to go offline, access to the storage at the failure location will be lost. If this is the non-AMS then you have lost your DR copy. If this is the AMS location, we are no in the situation where we must invoke a DR “application-failover”.
Once the application has been started at Location2, the AMS should be switched to make Location2 the new AMS. This ensures the application location matches the AMS and the system continues to operate from the “DR” location once the storage system has been fixed.
When the storage issue is resolved, the system will automatically begin re-synchronisation of the data from the current active location (DR) back to the old production site (Location1)
Once the production site (Location1) has been recovered, and the Storage Partition has returned to an “in-sync” state, the failback to the production site requires :
- Stop application at Location2 (DR)
- Failback the application and bring it up at Location1 (Production)
- Switch the AMS back to Location1 (Production)
- Resume the application I/O at Location1.
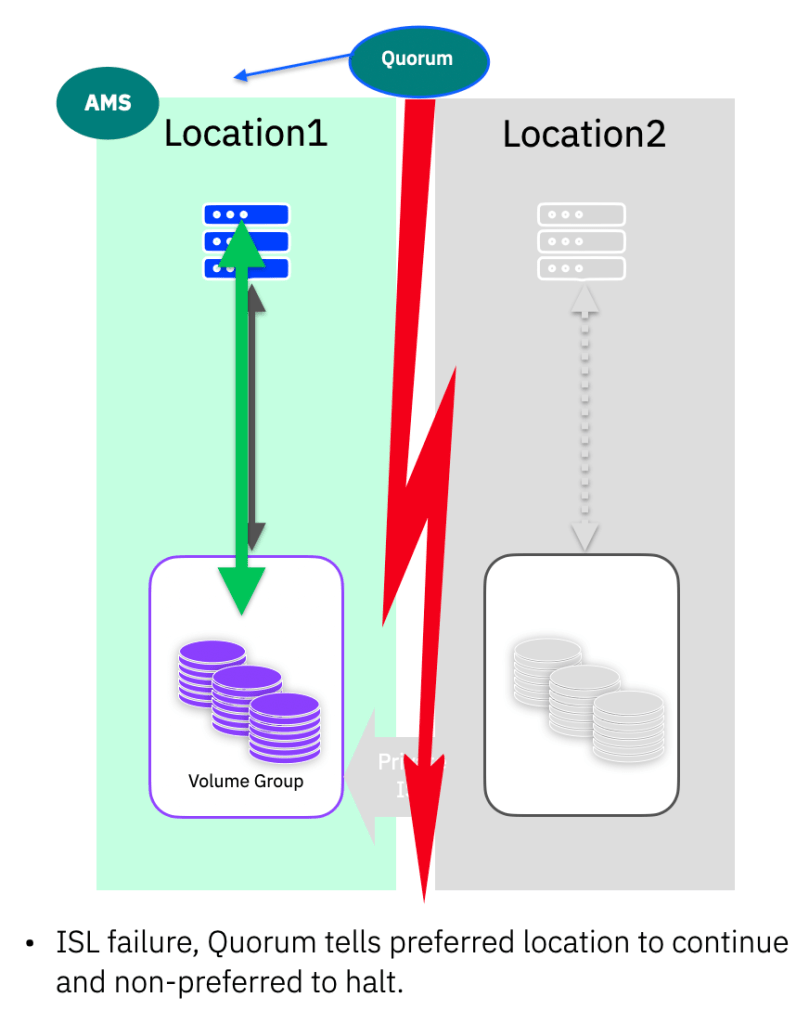
ISL Failure / Split brain
If the two storage systems lose contact with each other, then the IP Quorum is used to validate that both systems are still online. The AMS will be instructed to continue and the other system will take the paths to the volumes in the partition offline. Quorum is assessed on a per HA-partition pair basis, always following which location is the AMS for a given pair. (Unless of course one of the storage systems has of course failed – in that case the remaining system will continue as described in the previous section)
This is the reason it is imperative to ensure the AMS is allocated to the same location as where you are running the applications using volumes in this partition. If you get this wrong, the AMS (assuming it is available) will always win the quorum tie-break, then you could lose access if the application is actually running at the non-AMS location.
In normal running, there should be no impact to the applications, as the AMS location will win, and the DR location will be taken offline.
Part 3 Summary
In Part 3c we have looked at how you the system handles DR like configurations with a few considerations if you plan to use PBHA to provide a form of single direction, synchronous mirroring.
Across this whole series, we wanted to make sure people are armed with the possibilities that PBHA affords you, as well as things to consider as you plan and build your next gen High Availability solutions. Hopefully this information has proved useful and we will link this in the “How it works” section for future easy of search!





Leave a comment